Lewis A Baker, Faculty of Engineering and Physical Science, University of Surrey, UK
Distributed practice, a learning strategy that can inform curriculum design, deliberately spaces out opportunities for memory storage and retrieval of taught information to develop deep, robust and long-term learning for students (Dunlosky et al., 2013). Massed practice (better known to students as ‘cramming’), in contrast, involves material being studied for similar periods but without (or with little) spacing between such memory-storage-retrieval opportunities. In such cases, knowledge and skill competency are often forgotten. This translates clearly into assessment, where those who have learned in a ‘distributed curriculum’ compared to a ‘massed curriculum’ can show significant learning gains (Hattie, 2008) from the longer-lasting and deeper learning offered by spacing learning opportunities out, leading to what is referred to as the ‘distributed practice’, ‘spacing’ or ‘lag’ effect (Dunlosky et al., 2013). This effect is well documented in cognitive psychology (Latimier et al., 2020), having been demonstrated for students across ages and abilities, inside and outside of classroom environments (Agarwal, 2019; Nazari and Ebersbach, 2019), and is noted as one of the interventions that leads to the largest learning gains for students (Hattie, 2008). Why does distributed practice work, what does it look like and where does it happen in the curriculum?
The cognitive science view on memory and recall
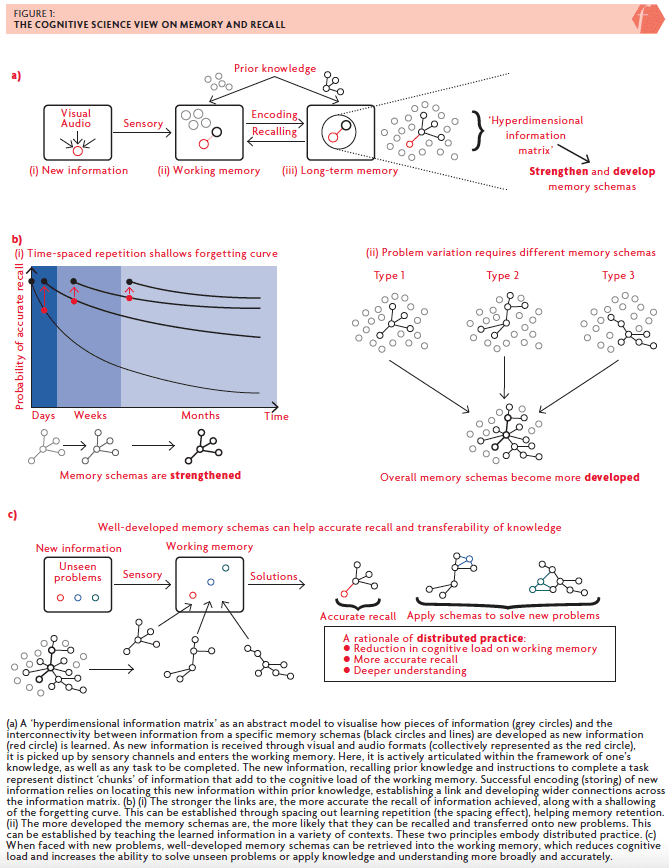
Memory is usually considered to have three phases: short-term, working and long-term memory (Cowan, 2008), although a distinction between the short-term and working memory will not be considered here. The working memory represents a memory space where information is held for short periods and can be manipulated through conscious cognitive processes (i.e. thinking). Cognitive load theoryAbbreviated to CLT, the idea that working memory is limited, as it is known, suggests that there is a limit to the information within the working memory. If distinct pieces of information (names, numbers, ideas, phrases, etc.) are considered ‘chunks’ of information (Hendrick and Macpherson, 2017), this limit is suggested to be around four chunks (Cowan, 2010). When new information is presented – images, text, speech, sounds, etc. (i.e. visual and audio information) – it is picked up by different sensory channels in the brain (see Figure 1a). As this new information is processed, it is expressed and articulated within the framework of one’s prior knowledge, which requires (sometimes significant) thinking. Through this, the new information, as well as the links to prior knowledge, is encoded (stored) in one’s long-term memory (Ginns, 2005). The process of encoding is itself an active area of research – for example, using distinct sensory channels (e.g. visual and audio) to help bypass some cognitive load limits in the process of ‘dual encoding’ (Herrlinger et al., 2017). Note, however, that this is not related to the learning stylesTheories relating to the idea that individuals learn best in neuromyth (Kirschner, 2017; Baker, 2020). Here, the long-term memory can be imagined as a ‘hyperdimensional information matrix’ – that is, several (possibly very different) types of information linked together in groups that represent specific memory structures, known as memory schemas (Ghosh and Gilboa, 2014). When faced with new information or a new problem, memory schemas can be retrieved (remembered) from the long-term memory and brought into the working memory to make progress. This is an iterative process; as new problems are solved, more information and deeper links are encoded into the long-term memory, which further develops the memory schemas, which can be relied upon in the future.
Distributed practice to construct well-developed memory schema
Recalling memory schemas causes a smaller cognitive load on one’s working memory, since it represents fewer chunks of information rather than several disconnected pieces of information (Hendrick and Macpherson, 2017), releasing the working memory to solve more complicated and abstract problems. There are two key steps for this to be successful. First, one must be able to retrieve the memory schema to use it. The second is being able to recognise where a memory schema can be applied. Forgetting information is a fact of life – it essentially comes down to practice: the more you practise retrieving memory schemas, the more likely that the next attempt at remembering will be successful. This is often referred to as the forgetting curve (Figure 1b(i)). To increase the probability of remembering or, more precisely, accurate recall, the schema needs to be recalled several times, the process of which strengthen the links between the information that makes it up. The value added of this effect is increased when these retrieval events are spaced out in time, from the first exposure to learning to, for example, the second exposure after minutes to days, the third exposure after days to weeks, and the fourth exposure after weeks to months. Although optimised spacing is dependent on the learning context, the deliberate use of spaced learning represents one key premise of distributed practice, leading to more successful and accurate recall.
Knowing when to recall and use a specific memory schema for a problem requires one to realise how one’s interconnected prior knowledge fits into the context of the problem that they face. The transferability of this schema, therefore, is only going to be successful when the schema itself is well developed – that is, more links are made across one’s knowledge base (Figure 1b(ii)). To achieve this, knowledge and skills need to be applied to a variety of different contexts so that the common themes and breadth of application may be understood. When an unseen problem is presented, there is a better chance that a well-developed schema will be seen as relevant and thus recalled and used to solve the problem (Figure 1c). This is captured by the second key premise of distributed practice: the use of a variety of problem types to broaden the scope within which knowledge is being learned increases the transferability of knowledge.
A curriculum informed by distributed practice
At the classroom level, distributed practice can be embedded through the use of a variety of problem types that require similar but perhaps unfamiliar situations to broaden the context of the information being presented. There are several informative posters that readers might find useful (Weinstein et al., nd), not affiliated with the author. Problem-solving using the taught information will provide an early opportunity for retrieval practice. A synopsis or starter activity in the next lesson (days or a week later) could provide the second retrieval opportunity. Of course, basic competency will need to be developed in what is being taught, as good practice such as modelling problem solutions and scaffoldingProgressively introducing students to new concepts to suppor student learning will help to demonstrate what well-developed memory schemas look like to students. This also helps to not overload students’ working memory (Rawson et al., 2015), which is the antithesis of such discovery learningAllowing learners to discover key ideas or concepts for them or minimal guidance approaches (Kirschner et al., 2006)! As the programme of study continues, building opportunities to revisit topics at later dates will help to reduce the probability of forgetting taught material. Multiple testing moments, as opposed to a single end-of-topic exam, can also be used to encourage more retrieval opportunities (Roediger et al., 2011).
At the programme level, spiral curricula have become more common, where topics are deliberately revisited sometime later after first exposure. However, this will only be effective if there have been retrieval opportunities in the interim; otherwise, leaving too much time between exposures will likely cause forgetfulness, cf Figure 1b(i) (Benjamin and Tullis, 2010). InterleavingAn approach to learning where, rather than focusing on one p is a useful technique, where different topics are organised in such a way as to break up mass practice of any one topic (Rohrer, 2012). For example, if three topics (A, B and C) are to be covered over nine teaching sessions, an order of study such as ABC BCA CAB, rather than AAA BBB CCC, would embody this principle. Lagged homework is another technique, where the topic of one homework does not match that week’s taught material (Hendrick and Macpherson, 2017).
While some of these approaches will represent small adjustments to what is already being delivered across programmes or within the classroom, others can represent quite significant planning and logistical challenges that require cooperation across many stakeholders. However, this is not in vain; when left to their own devices, students do not usually make use of effective learning strategies (Dirkx et al., 2019). Instead, students tend to default to mass practice of one topic at a time when close to an assessment (not strengthening memory schemas through retrieval practice) and revert to copying or highlighting notes for revision (not developing memory schemas through varied problem types). As such, deliberately building in distributed practice is important, as a student is unlikely to do it themselves and reap the benefits!